Este año, el tráfico superó los 115.8 mil millones de solicitudes, un crecimiento interanual del 33.6%, con un desempeño consistente en todo momento.
La forma del tráfico contó una historia familiar: una caída en Thanksgiving cuando la gente se aleja de las pantallas, seguida por un repunte en Black Friday, niveles elevados durante el fin de semana y una segunda ola marcada en Cyber Monday.
Estos patrones se repitieron en todas las geografías principales, en el caso de la plataforma Vercel se adaptó de manera continua, sin cambios de configuración ni intervención manual.
A continuación, una vista rápida del fin de semana:
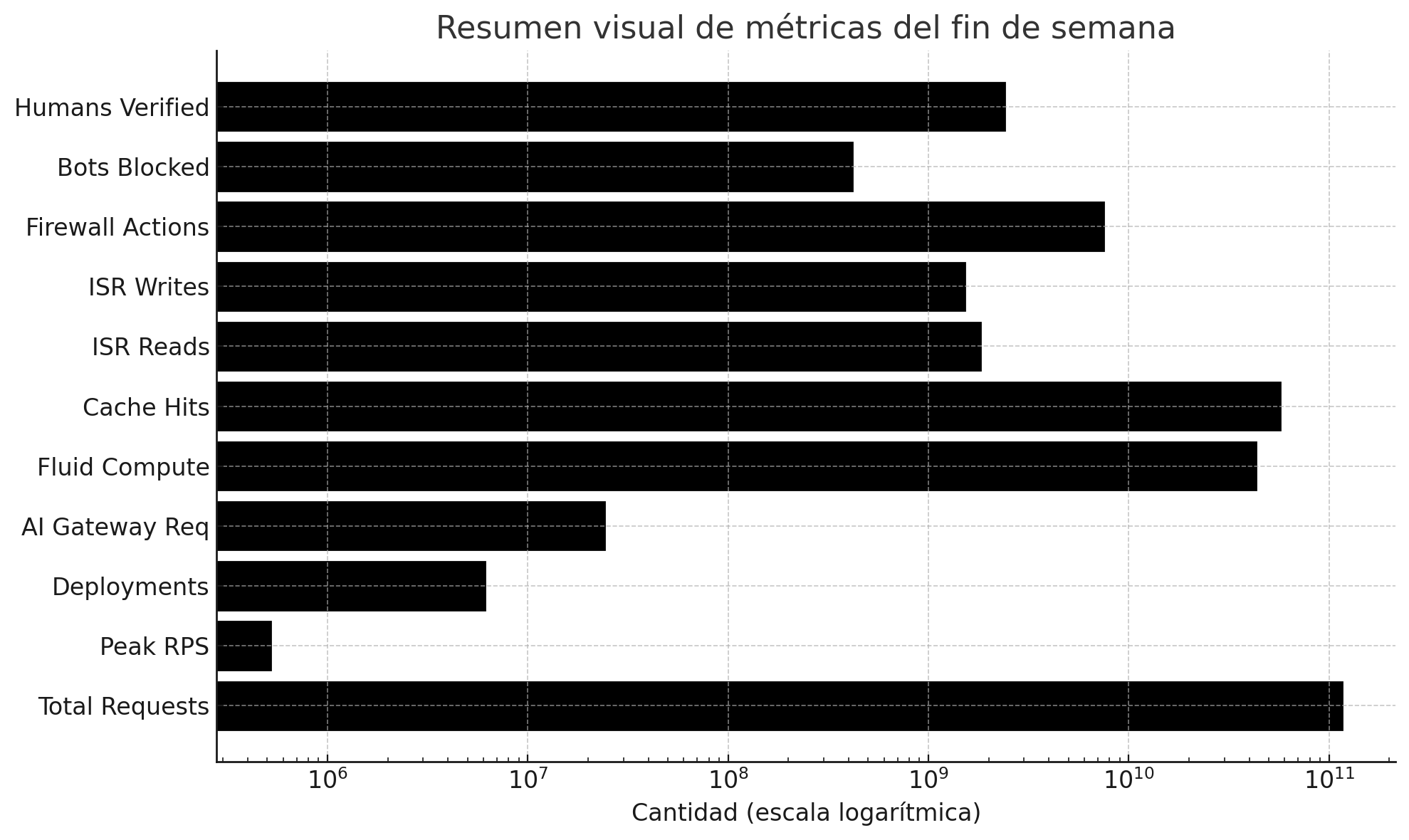
Métricas clave del fin de semana
- 115,836,126,847 solicitudes totales — Tráfico global entregado con desempeño consistente.
- 518,027 solicitudes por segundo (pico) — Tráfico manejado en la demanda más alta.
- 6,120,247 despliegues — Nuevas versiones de aplicaciones enviadas a producción.
- 24,086,391 solicitudes al AI Gateway — Enrutamiento de IA optimizado para respuestas rápidas entre proveedores.
- 43,213,555,901 invocaciones de Fluid Compute — Workloads dinámicos que escalaron automáticamente.
- 56,926,096,915 aciertos de caché — Entrega acelerada desde regiones distribuidas globalmente.
- 1,809,912,897 lecturas ISR — Cargas iniciales de contenido actualizado (sin contar respuestas cacheadas).
- 1,517,476,504 escrituras ISR — Actualizaciones de catálogos, precios y contenido propagadas al instante.
- 7,507,223,309 acciones del firewall — Amenazas filtradas antes de llegar a las aplicaciones.
- 415,683,895 bots bloqueados — Abuso automatizado detenido desde la primera capa.
- 2,408,122,336 humanos verificados — Compradores legítimos confirmados mediante controles de seguridad.
- Regiones con mayor actividad: US, DE, GB, IN, BR, SG, JP — con alta demanda en las 20 regiones globales.
¿Cómo puede soportar tanto tráfico una aplicación así?
La clave está en la arquitectura subyacente: una combinación de computación distribuida, escalado automático, redes globales de baja latencia y un diseño sin puntos únicos de falla. En lugar de depender de un servidor o instancia fija, la aplicación se ejecuta sobre una red de regiones que pueden aumentar capacidad bajo demanda, replicar contenido de forma inteligente y dirigir las solicitudes al punto más cercano al usuario.
En Stackfire ayudamos a crear aplicaciones capaces de operar bajo tráfico extremo mediante arquitecturas modernas basadas en microservicios y despliegue distribuido en la nube. Nuestro enfoque combina:
- Backends desacoplados y escalables, diseñados como microservicios que pueden crecer de forma independiente.
- Infraestructura serverless y autoescalable, similar a la que utilizan plataformas como Vercel, donde la capacidad se adapta en tiempo real sin intervención manual.
- Despliegues globales, replicando servicios y contenido en múltiples regiones para reducir latencia y absorber picos de demanda.
- Pipelines de automatización, que permiten enviar nuevas versiones de tus servicios con seguridad, rapidez y sin interrupciones.
- Observabilidad y resiliencia, con métricas, logs y alertas en tiempo real que permiten detectar y resolver problemas antes de que afecten a los usuarios.
Con este modelo, las aplicaciones que construimos o modernizamos para nuestros clientes no dependen de un solo servidor ni de una arquitectura monolítica rígida. En su lugar, funcionan sobre un entorno distribuido, elástico y tolerante a fallos que sigue respondiendo incluso bajo millones de solicitudes por segundo.
En esencia, ayudamos a que tu backend opere con la misma robustez y flexibilidad que las plataformas modernas a escala global.